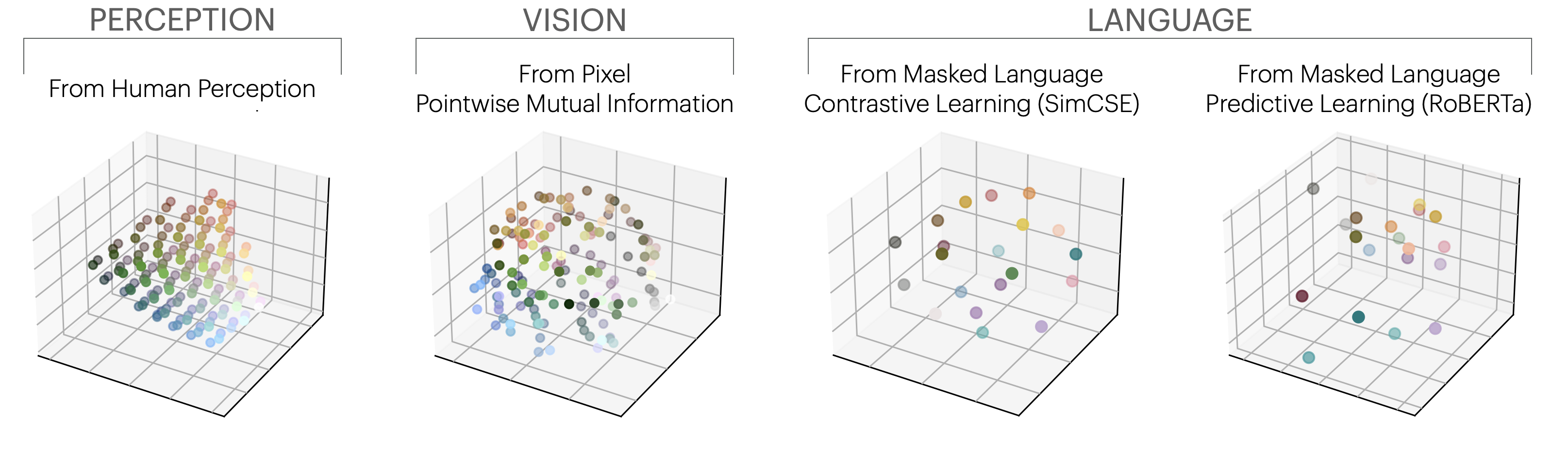
Conventionally, different AI systems represent the world in different ways. A vision system might represent shapes and colors,
a language model might focus on syntax and semantics. However, in recent years, the architectures and objectives
for modeling images and text, and many other signals, are becoming remarkably alike.
Are the internal representations in these
systems also converging?
We argue that they are, and put forth the following hypothesis:
Neural networks, trained with different objectives on different data and modalities,
are converging to a shared statistical model of reality in their representation spaces.
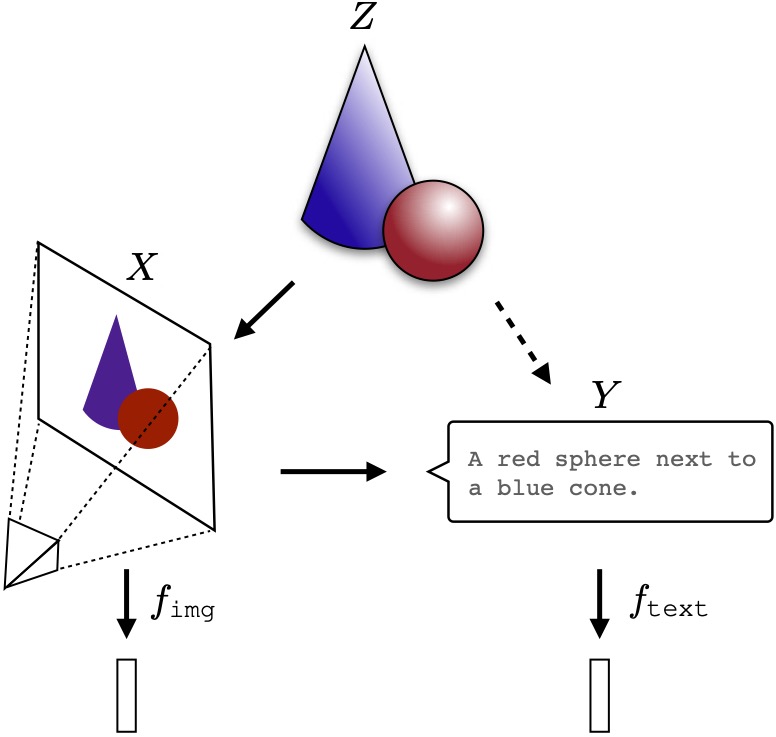
The intuition behind our hypothesis is that all the data we consume -- images, text, sounds, etc -- are projections of
some underlying reality. A concept like
can be viewed in many
different ways but the meaning, what is represented, is roughly
* the same. Representation learning algorithms might recover
this shared meaning.