|
|
|
|
|
|
|
|
|
|
|
 |
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros Image-to-Image Translation with Conditional Adversarial Networks CVPR, 2017 (Paper) |
|
|
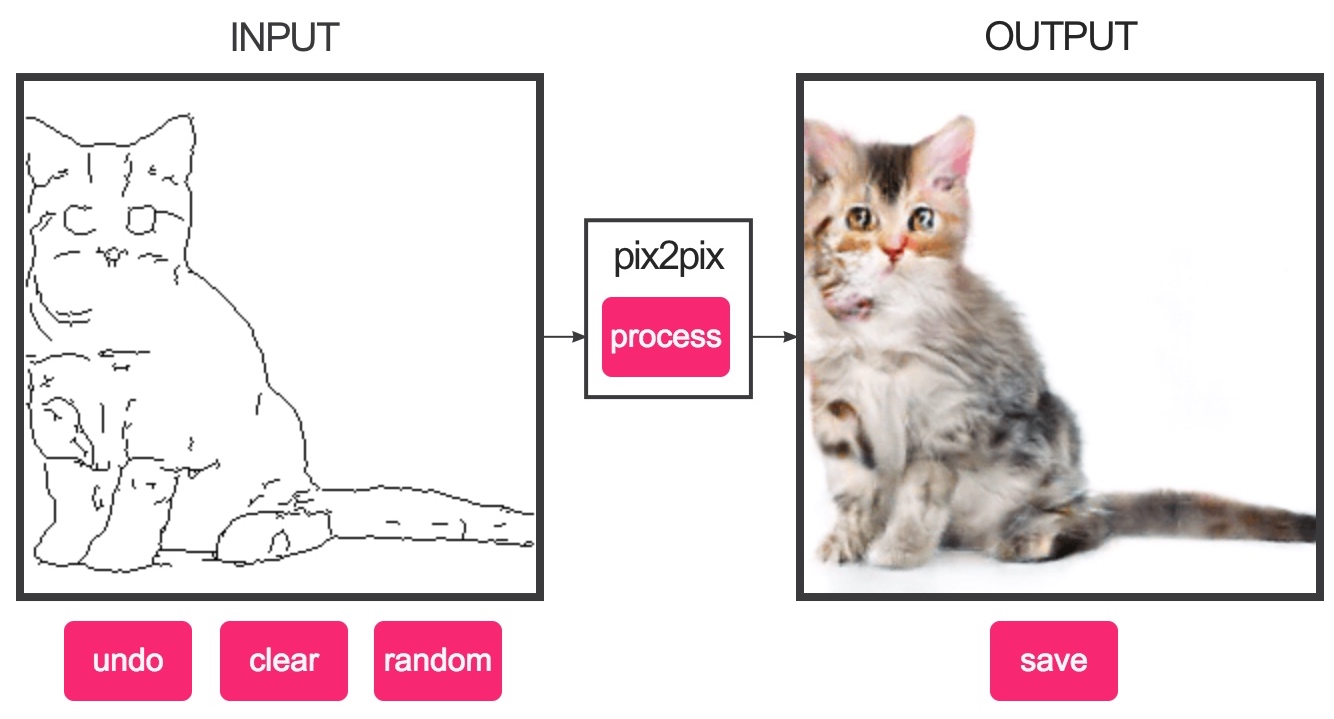
Interactive Demo |
|
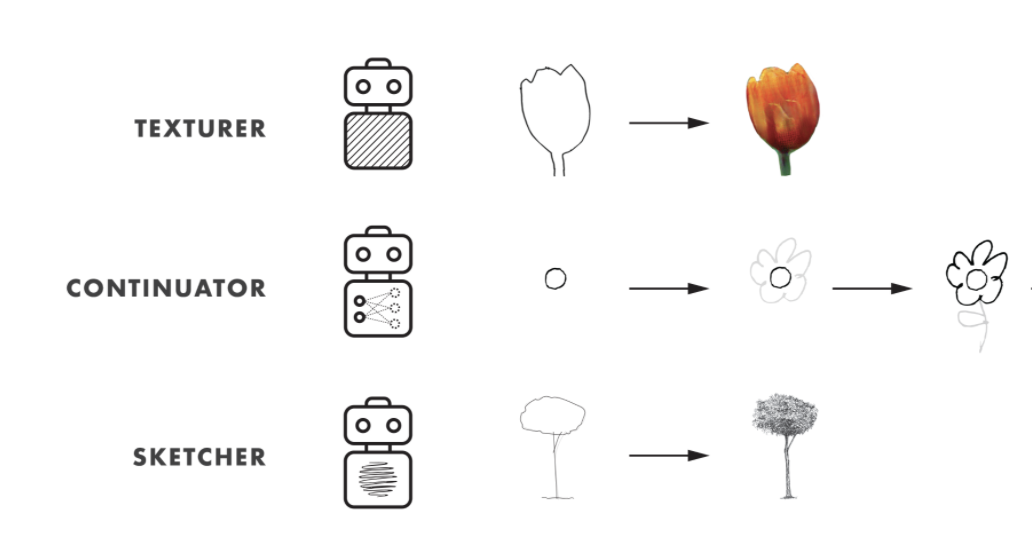
Karoly Zsolnai-Feher made the above as part of his very cool "Two-minute papers" series.
|
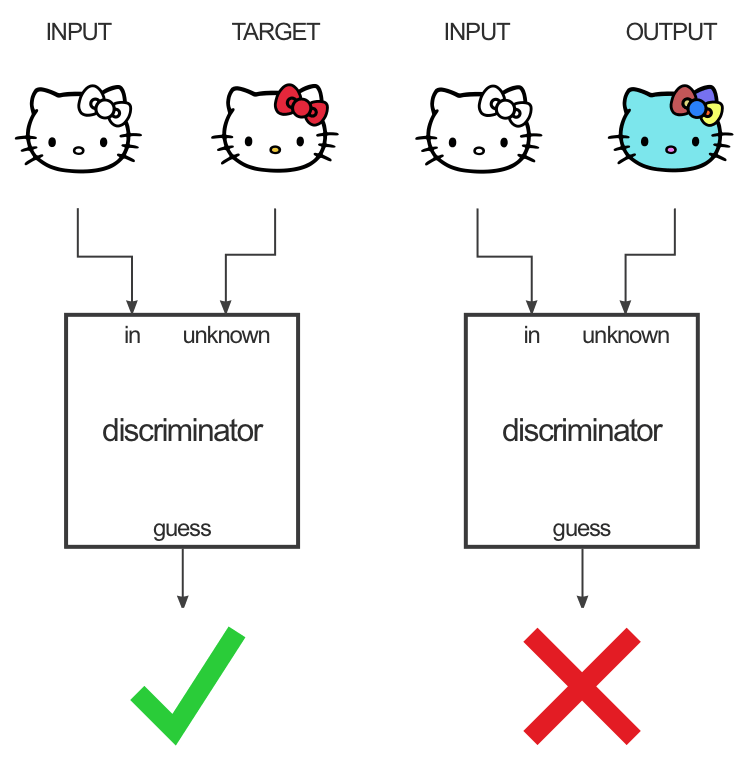 Great explanation by Christopher Hesse, also documenting his tensorflow port of our code. |
|
Effect of the objective Cityscapes Facades Effect of the generator architecture Cityscapes Effect of the discriminator patch scale Cityscapes Facades |
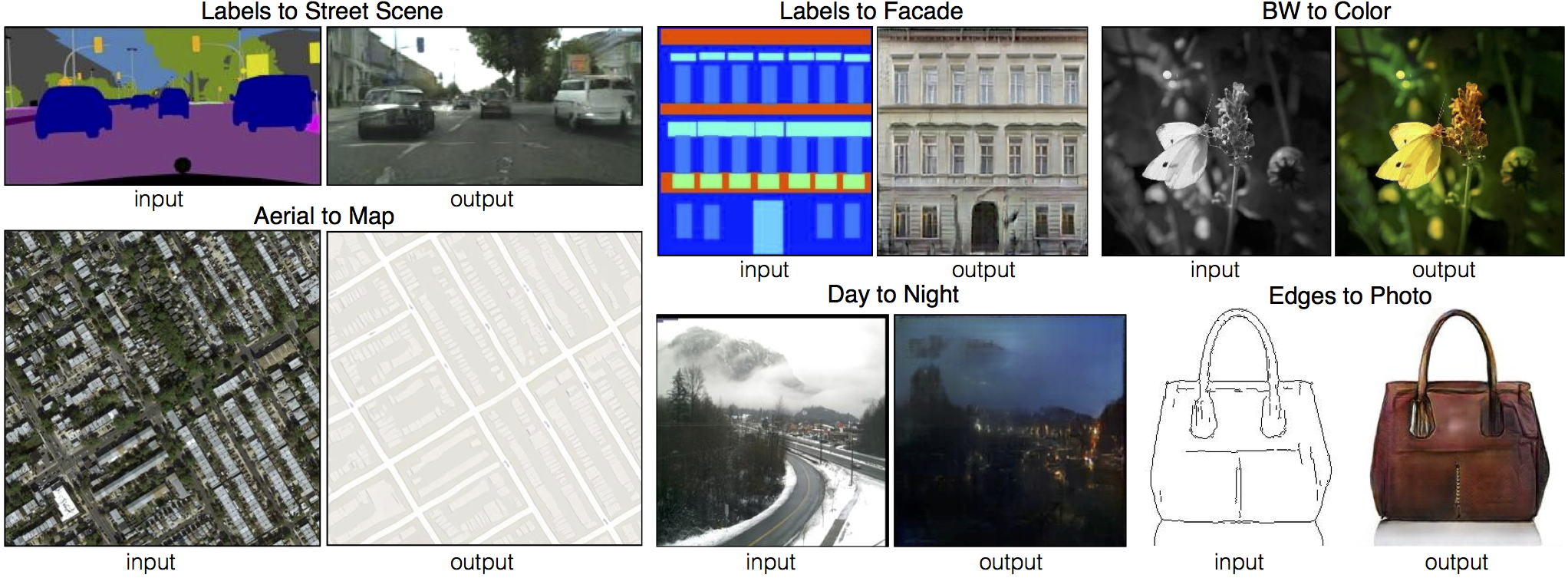
Additional results Map to aerial Aerial to map Semantic segmentation Day to night Edges to handbags Edges to shoes Sketches to handbags Sketches to shoes |
Community contributions: #pix2pix
|
Recent Related WorkIan J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative Adversarial Networks. NIPS, 2014. [PDF] Alec Radford, Luke Metz, Soumith Chintala. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. ICLR, 2016. [PDF][Code] Jun-Yan Zhu, Philipp Krahenbuhl, Eli Shechtman, Alexei A. Efros. Generative Visual Manipulation on the Natural Image Manifold. ECCV, 2016. [PDF][Webpage][Code] |
|
Also, please check out our follow-up work on image-to-image translation *without* paired training examples: Jun-Yan Zhu*, Taesung Park*, Phillip Isola, Alexei A. Efros. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. ICCV, 2017. [PDF][Webpage][Code] |
Acknowledgements |